BASES DE DATOS NOSQL

¿Qué hace a NoSQL diferente?
Una diferencia clave entre las bases de datos de NoSQL y las bases de datos relacionales tradicionales, es el hecho de que NoSQL es una forma de almacenamiento no estructurado.
Esto significa que NoSQL no tiene una estructura de tabla fija como las que se encuentran en las bases de datos relacionales.
Ventajas y desventajas de las bases de datos NoSQL
Ventajas
Las bases de datos de NoSQL presentan muchas ventajas en comparación con las bases de datos tradicionales.
- A diferencia de las bases de datos relacionales, las bases de datos NoSQL están basadas en key-value pairs
- Algunos tipos de almacén de bases de datos NoSQL incluyen diferentes tipos de almacenes como por ejemplo el almacén de columnas, de documentos, de key value store, de gráficos, de objetos, de XML y otros modos de almacén de datos.
- Algunos tipos de almacén de bases de datos NoSQL incluyen almacenes de columnas, de documentos, de valores de claves, de gráficos, de objetos, de XML y otros modos de almacén de datos.
- Podría decirse que las bases de datos NoSQL de código abierto tienen una implementación rentable. Ya que no requieren las tarifas de licencia y pueden ejecutarse en hardware de precio bajo.
- Cuando trabajamos con bases de datos NoSQL, ya sean de código abierto o tengan un propietario, la expansión es más fácil y más barata que cuando se trabaja con bases de datos relacionales. Esto se debe a que se realiza un escalado horizontal y se distribuye la carga por todos los nodos. En lugar de realizarse una escala vertical, más típica en los sistemas de bases de datos relacionales.
- Por supuesto, las bases de datos NoSQL no son perfectas, y no siempre van a ser la elección ideal.
- La mayoría de las bases de datos NoSQL no admiten funciones de fiabilidad, que son soportadas por sistemas de bases de datos relacionales. Estas características de fiabilidad pueden resumirse en: “atomicidad, consistencia, aislamiento y durabilidad.” Esto también significa que las bases de datos NoSQL, que no soportan esas características, ofrecen consistencia para el rendimiento y la escalabilidad.
- Con el fin de apoyar las características de fiabilidad y coherencia, los desarrolladores deben implementar su propio código, lo que agrega más complejidad al sistema.
- Esto podría limitar el número de aplicaciones en las que podemos confiar para realizar transacciones seguras y confiables, como por ejemplo los sistemas bancarios.
- Otras formas de complejidad encontradas en la mayoría de las bases de datos NoSQL, incluyen la incompatibilidad con consultas SQL. Esto significa que se necesita un lenguaje de consulta manual, haciendo los procesos mucho más lentos y complejos.

MongoDB
MongoDB es una base de datos libre de esquemas, orientada a documentos, escrita en C ++. La base de datos está basada en el almacén de documentos, lo que significa que almacena valores (denominados documentos) en forma de datos codificados.
La elección del formato codificado en MongoDB es JSON. Es muy potente, porque incluso si los datos están anidados dentro de los documentos JSON, seguirá siendo consultable e indexable.
Las subsecciones que siguen, describen algunas de las características clave disponibles en MongoDB.

Shards / Fragmentos
Sharding es la partición y distribución de datos a través de múltiples máquinas (nodos). Un fragmento, es una colección de nodos MongoDB. A diferencia que Cassandra, donde los nodos estaban simétricamente distribuidos.
El uso de fragmentos también implica la capacidad de escalar horizontalmente a través de múltiples nodos. En el caso de que haya una aplicación que utilice un único servidor de base de datos, se puede convertir en clúster fragmentado, con muy pocos cambios en el código de la aplicación original, por la forma en que Sharding es ejecutada por MongoDB. Oftware está casi desacoplado de las API públicas.
Lenguaje de consulta Mongo
Como se mencionó anteriormente, MongoDB utiliza una API RESTful. Para recuperar ciertos documentos de una colección db, se crea un documento de consulta que contiene los campos que deben coincidir con los documentos deseados.
Acciones
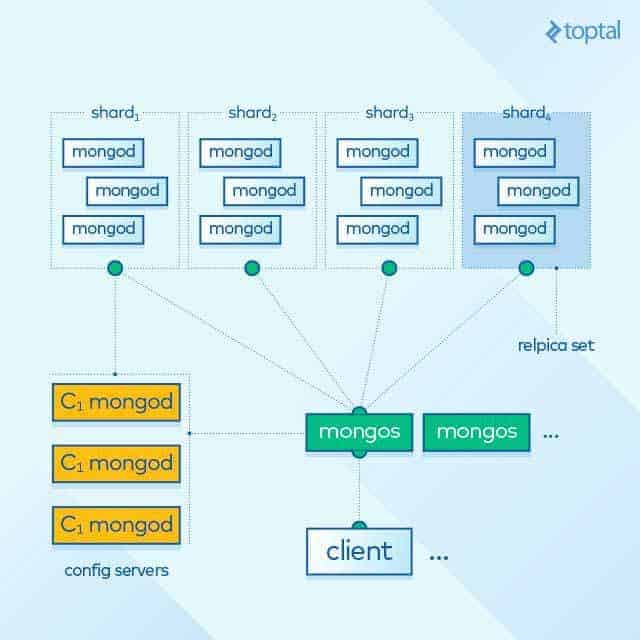
En MongoDB, hay un grupo de servidores llamados enrutadores. Cada uno actúa como un servidor para uno o más clientes. Del mismo modo, el clúster contiene un grupo de servidores denominados servidores de configuración. Cada uno contiene una copia de los metadatos que indican qué fragmento contiene qué datos. Las acciones de lectura o escritura se envían desde los clientes a uno de los servidores de enrutador del clúster y son encaminadas automáticamente por ese servidor, a los fragmentos adecuados que contienen los datos con la ayuda de los servidores de configuración.
Un fragmento en MongoDB similar a Cassandra es que ambos tienen un esquema de replicación de datos, que crea un conjunto de réplicas de cada fragmento que contiene exactamente los mismos datos.
Hay dos tipos de esquemas de réplica en MongoDB: Master-Slave replication y Replica-Set replication. Replica-Set proporciona más automatización y mejor manejo para los fallos, mientras que Master-Slave suele requerir la intervención de un administrador. Independientemente del esquema de replicación, en cualquier punto de conjunto de réplicas, sólo un fragmento actúa como fragmento primario. Todos los fragmentos de réplica son fragmentos secundarios. Todas las operaciones de escritura y lectura pasan al fragmento primario y luego se distribuyen de forma uniforme, (si fuera necesario), a los otros fragmentos secundarios del conjunto.
En el gráfico de abajo, vemos la arquitectura de MongoDB explicada anteriormente, mostrando los servidores del enrutador en verde, los servidores de configuración en amarillo y los fragmentos que contienen los nodos MongoDB en azules.
VENTAJAS
Validación de documentos
Motores de almacenamiento integrado
Menor tiempo de recuperación ante fallas
DESVENTAJAS
No es una solución adecuada para aplicaciones con transacciones complejas
No tiene un reemplazo para las soluciones de herencia
Aún es una tecnología joven
MARIADB
MariaDB siempre se lanzó como un "puente" entre las bases de datos MySQL y NoSQL como Cassandra y LevelDB. Ahora, MariaDB Foundation ha lanzado la versión 10 de la base de datos de código abierto, incorporando varias capacidades NoSQL-esque que hacen de MariaDB Enterprise 2 un paquete más atractivo.
La gran adición es el motor Connect, que proporciona acceso rápido a archivos no estructurados, por ejemplo, archivos de registro en una carpeta, desde MariaDB. También se puede acceder a los datos de Cassandra desde MariaDB 10, y las "columnas dinámicas" también permiten el almacenamiento al estilo NoSQL de objetos con etiquetas diferentes en cada fila. Aparte de eso, MariaDB 10 también es supuestamente mucho más rápido y más estable que las versiones anteriores.
El jefe de ventas de SkySQL, Dion Cornett, me sugirió que los usuarios empresariales encontrarían valor en poder unir los diversos formatos de archivos y datos que podrían encontrar.
"¿Qué sucede si su tienda en línea vende y cumple pedidos de una amplia gama de proveedores diferentes, y sus sistemas deben acceder y combinar sus registros de inventario, almacenados en diferentes bases de datos SQL, desde Oracle a MySQL a PostgreSQL a SQL Server?", Planteó Cornett. "La combinación de fuentes de datos tan diferentes en tiempo real ha requerido mucha lógica codificada a mano, una propuesta costosa y que requiere mucho tiempo".
En cuanto a MariaDB Enterprise Cluster 2, una nueva consola de usuario y API de administración tiene como objetivo simplificar la implementación de clústeres Galera, un movimiento que debería atraer a aquellos con necesidades de alta disponibilidad.
No hay comentarios:
Publicar un comentario